
――ベンチマークの数字が独り歩きする時、私たちは何を読み取るべきか
2026年の幕開けとともに、テクノロジーメディアのWccftechが刺激的な見出しを報じました。
「NVIDIA GB200 NVL72が、AMDの競合製品MI355Xを28倍も圧倒した」というものです。
しかもそれは、単なる処理速度ではなく、投資対効果(Intelligence per Dollar)における差であるとされています。
「NVIDIA GB200 NVL72、AMD MI355Xを28倍も圧倒する驚愕の性能――『1ドルあたりの知能(性能)』で市場をリード」

しかし「28倍」という数字は、CPUやGPUの性能競争においてあまりに非現実的です。GearTune編集部はこの極端な値に対して比較条件から疑いの目を向けました。
「28倍」は捏造ではないが、一般論に当てめられるわけでもない
まず、公平を期すために明言しておきますが、Wccftechが数字を捏造したわけではありません。
この数値の根拠は、アナリスト企業Signal65が発表したレポート『From Dense to Mixture of Experts: The New Economics of AI Inference』の中に実在します。
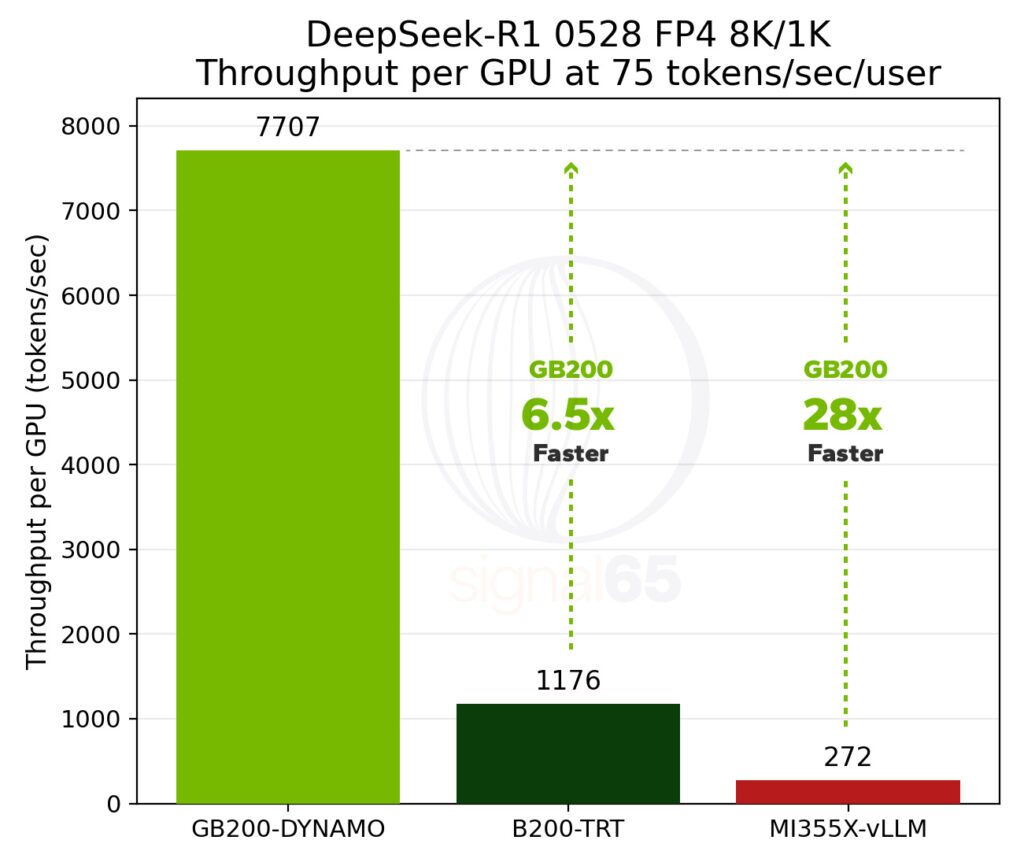
Signal65の一次資料には、確かに「GB200 NVL72は競合するMI355Xプラットフォームに対し、最大28倍のパフォーマンスを提供する」という旨の記述があります。
【原文】
On a per-GPU basis, the MI355X is roughly half the price of the GB200 NVL72 configuration, but since GB200 NVL72 provides a per-GPU performance advantage ranging from nearly 6x at the low end, to as high as 28x at a higher interactivity rate, the NVIDIA platform still offers up to 15x the performance per dollar compared to AMD’s current offering. Put another way, NVIDIA can offer a relative cost per token that is 1/15th that of the competition.
【翻訳】
GPU単体の価格で見れば、MI355XはGB200 NVL72構成のおよそ半額にすぎません。しかし、GB200 NVL72はGPUあたりの性能で圧倒しており、差が少ない場合でも約6倍、高い応答速度(インタラクティビティ)が求められる場面では最大28倍もの優位性を発揮します。
このため、NVIDIAのプラットフォームはAMDの現行製品に対し、『対費用性能(1ドルあたりのパフォーマンス)』で最大15倍もの価値を提供することになります。言い換えれば、NVIDIAは競合他社の15分の1というコストで、1トークンを生成できるということです。
しかし、重要なのはその数字が存在するかどうかではなく、その数字が「どのような条件下で生まれたか」です。
28倍という数字を生み出した「極端な条件」
Signal65の分析データを詳細に確認すると、28倍という差が生じるには、極めて特殊な前提条件が必要であることがわかります。
1. 厳しい応答速度(SLA)の壁
この比較は、単なる最大性能(ピーク性能)の勝負ではありません。「1ユーザーあたり毎秒75トークン」という、非常に高い応答性を維持できるかどうかのテスト結果です。
生成AIにおいて、毎秒75トークンという速度は、人間が文字を読む速度を遥かに上回る極めて高速なレスポンスです。
レポートのデータによれば、この厳しい条件を課した際、AMDのシステムはその基準を満たすことが困難になり、結果としてNVIDIAとの差が劇的に開いたことを示唆しています。

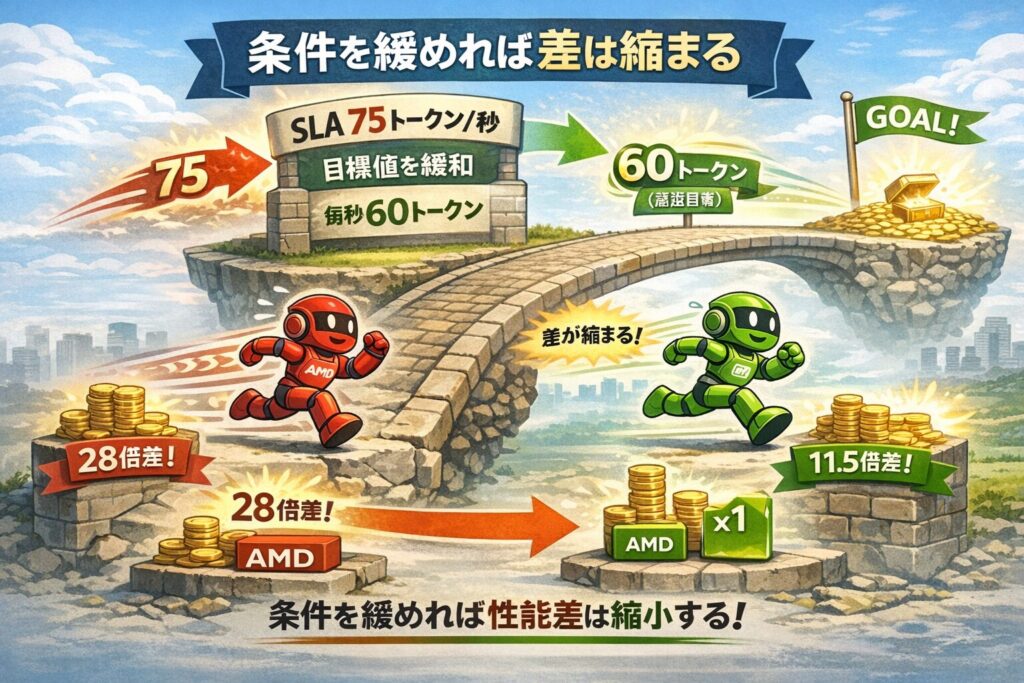
2. 条件を緩めれば差は縮まる
興味深いことに、同じレポート内で条件を少し緩め、「毎秒60トークン」という(それでも十分に高速な)目標値に設定した場合、性能差は「11.5倍」となります。
28倍から11.5倍への急激な変化は、何を意味するのでしょうか。
それは、NVIDIAのGB200が「あらゆる場面で28倍速い」わけではなく、「AMDが特定の厳しい基準(SLA)を維持できなくなった領域でも、NVIDIAは性能を維持し続けた」という、限界領域での挙動の違いを表しています。
「同様のクラスター構成」という言葉の罠
もとの記事の中で見過ごせないのが、「同様のクラスター構成(similar cluster configuration)」という表現です。
現代のAI推論、特にMixture of Experts(MoE)モデルにおいては、GPU単体の性能と同じくらい、GPU同士を繋ぐ「通信」が重要になります。
- NVIDIA GB200 NVL72: 72基のGPUをNVLinkによってひとつの巨大なGPUとして動作させ、最大130TB/sという驚異的な帯域幅で接続しています。
- AMD MI355X: 従来型のネットワーク接続(EthernetやInfiniBand)で構成されたクラスターである可能性が高く、通信速度の面でボトルネックが生じやすい構造です。
つまり、これは純粋な「チップ対チップ」の戦いではなく、「ラック全体を一つのチップとして設計したシステム」対「従来のサーバー連結システム」の戦いと言えます。
条件が「Similar(同様)」であるかどうかは、議論の余地が大いにあります。
ラックスケール・コンピューティングの時代の到来
とはいえ、NVIDIAが「ラックスケール(棚単位)」での設計において、AMDに先行していることは疑いようのない事実です。
GB200 NVL72のアドバンテージは、GPU単体の計算力以上に、72個のGPUがあたかも1つの巨大な脳として振る舞える点にあります。
大規模なMoEモデルを扱う際、この設計思想の差は決定的な違いを生みます。
Signal65のレポートは、NVIDIAのこの「Extreme Co-Design(極限までの統合設計)」が、特定の高負荷な推論ワークロードにおいて圧倒的に有利であることを正しく指摘しています。
しかし、それが一般的なすべてのAIワークロードにおいて28倍の差を保証するものではありません。
























結論:見出しの向こう側を読むリテラシー
今回の「28倍」報道から学ぶべきは、NVIDIAの圧倒的な強さだけではなく、ベンチマーク記事の読み解き方です。
- 数字は嘘をつかないが、条件は隠れることがある。
- 「最大○倍」という表現は、競合他社が失速した特定のポイントを指している場合が多い。
- AIハードウェアの競争は、すでにチップ単体ではなく、通信を含むシステム全体の競争に移行している。
現時点において、GB200 NVL72がAIインフラの頂点にあることは間違いありません。しかし、技術選定や市場動向を正しく理解するためには、センセーショナルな見出しに踊らされることなく、「どの条件で、なぜその差が生まれたのか」という地味で複雑な文脈を理解する必要があります。
AIモデルがDense(密)からMoE(疎)へと進化したように、私たちの情報の受け取り方もまた、単純な数字の比較から、より多角的な分析へと進化させる時期に来ているのかもしれません。
GearTuneをチェックして最新ニュースをお見逃しなく。